Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms.
Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential.
To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories.
In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization.
To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies.
Dataset
tulliomf (Brasil)
kosanka (Mali)
benjidad (Indonesia)
arizalkawamuna (Indonesia)
plannerqadeer for City Pulse (Pakistan)
sedicla (Chile)
vik1607 (Kazakstan)
mapillario (China)
kmajcher for Here (Sweden)
vbombaerts (Oman)
caesium (Japan)
3stripes (New Zealand)
themadcabbie (England)
canadarunner (Utah)
weinshaum (Australia)
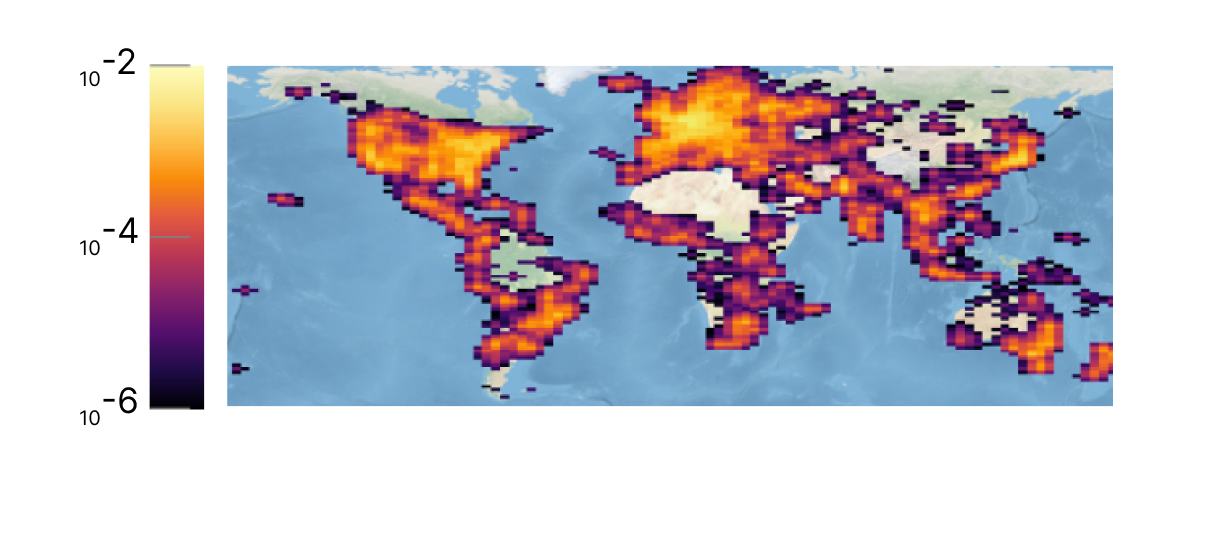
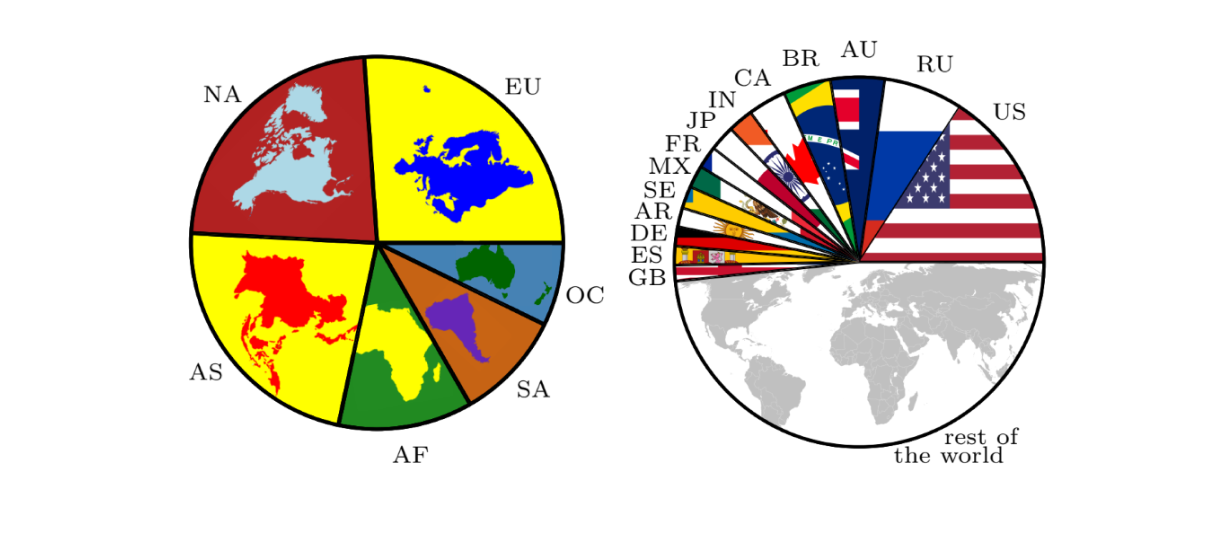
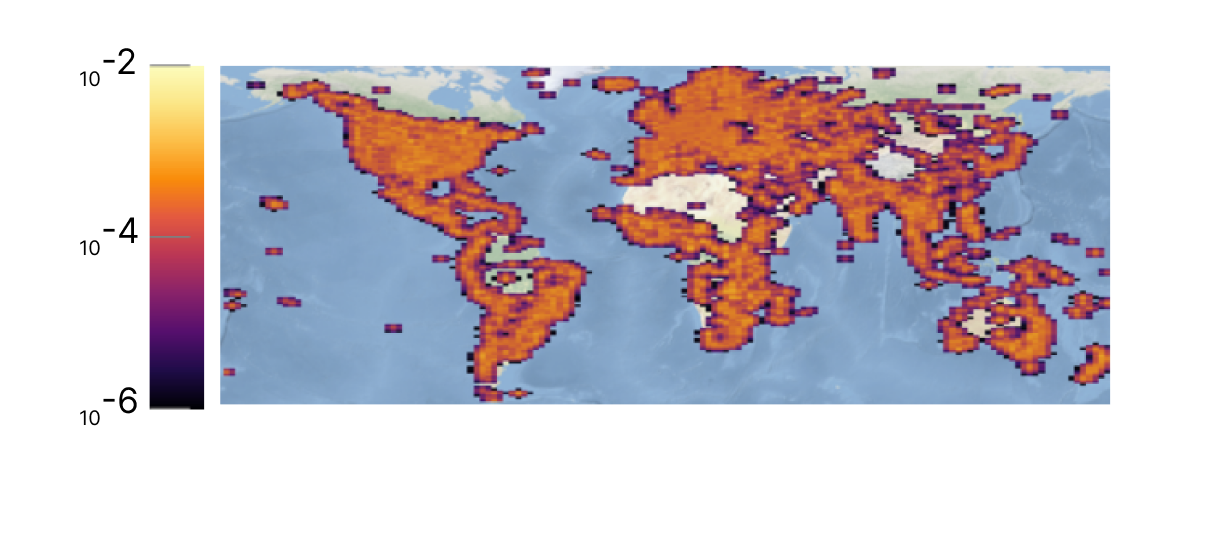
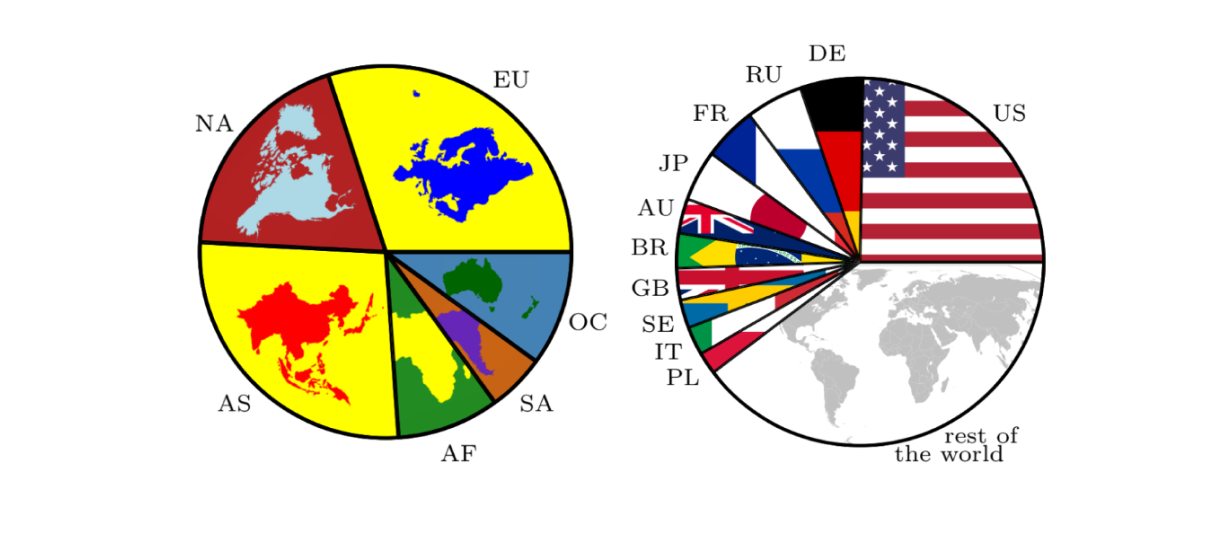
Our dataset offers a wide variety of images, from urban to rural areas, well distributed across the globe.
We especially curate our dataset to fit as close as possible the real global spatial population density, with a priority on the test set.
We enforce a train and test spatial separation (1km) and keep only one image per capture sequence.
This means that the network cannot simply rely on memorizing places in order to geolocate images, but has to learn geographical features that represent countries and regions.
Train Density
Train Distribution
Test Density
Test Distribution
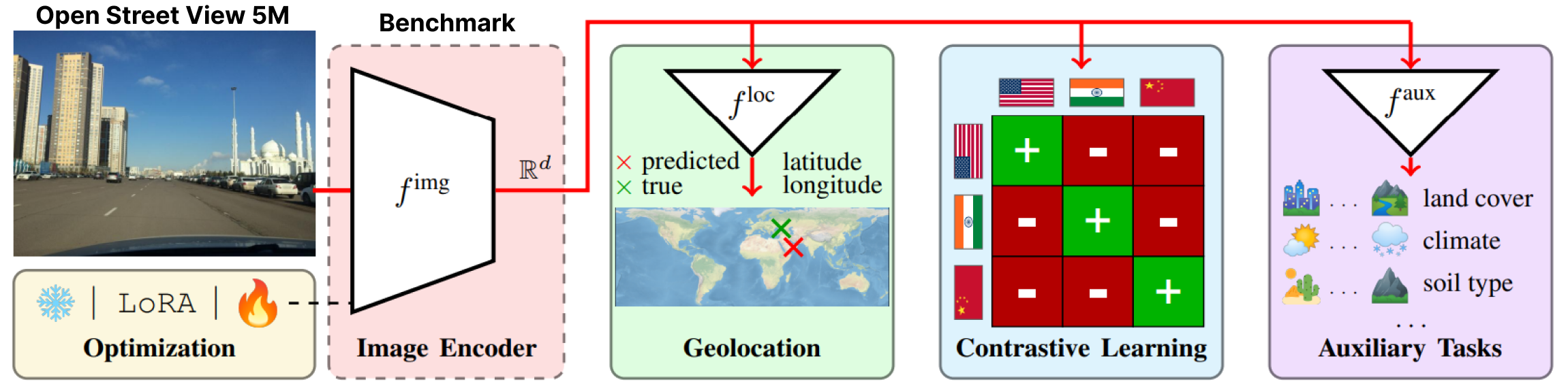
Benchmark
We benchmark various state-of-the-art image encoders, output representations, training losses, and parameter finetuning strategies on our dataset.
By selecting the best performing components from each step, we propose a strong baseline for visual geolocation on OSV-5M.
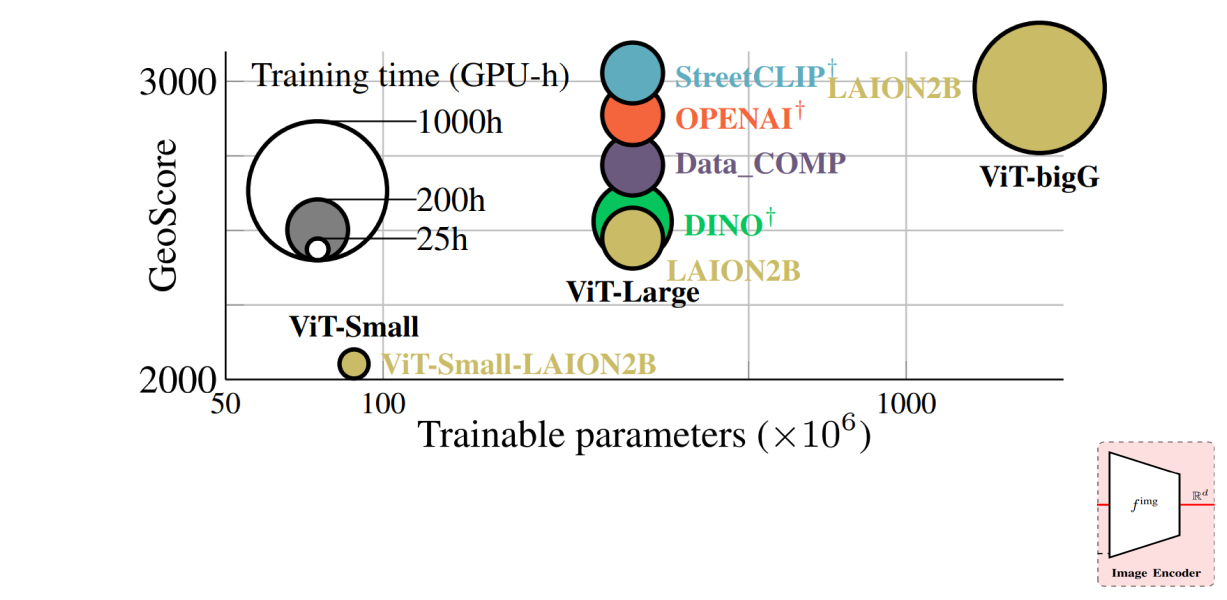
Backbone
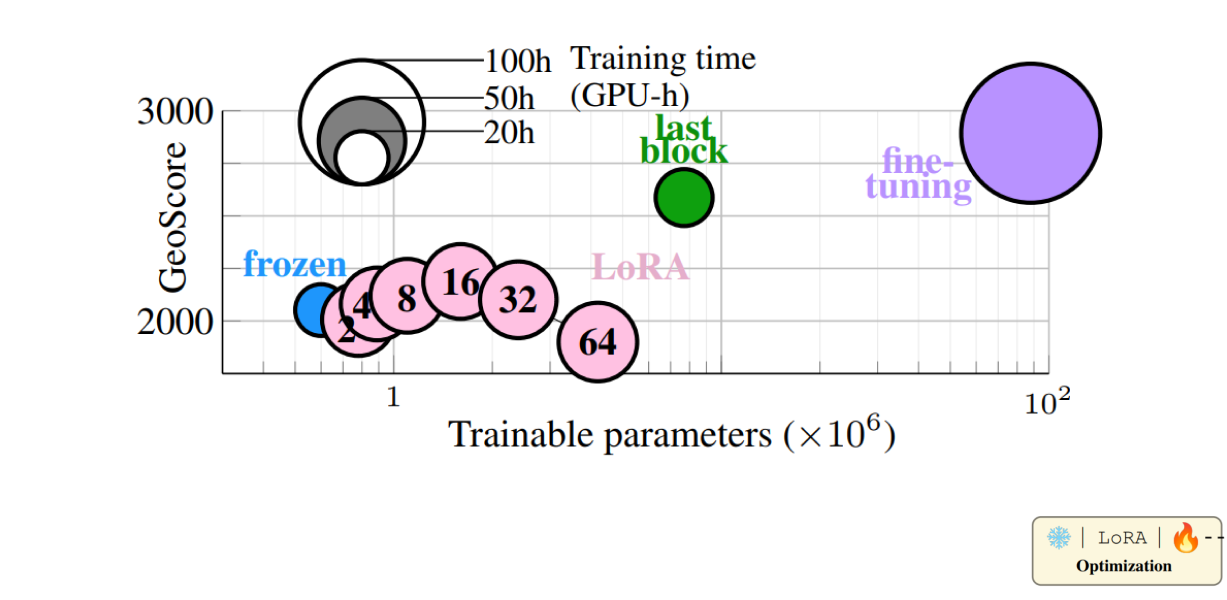
Finetuning
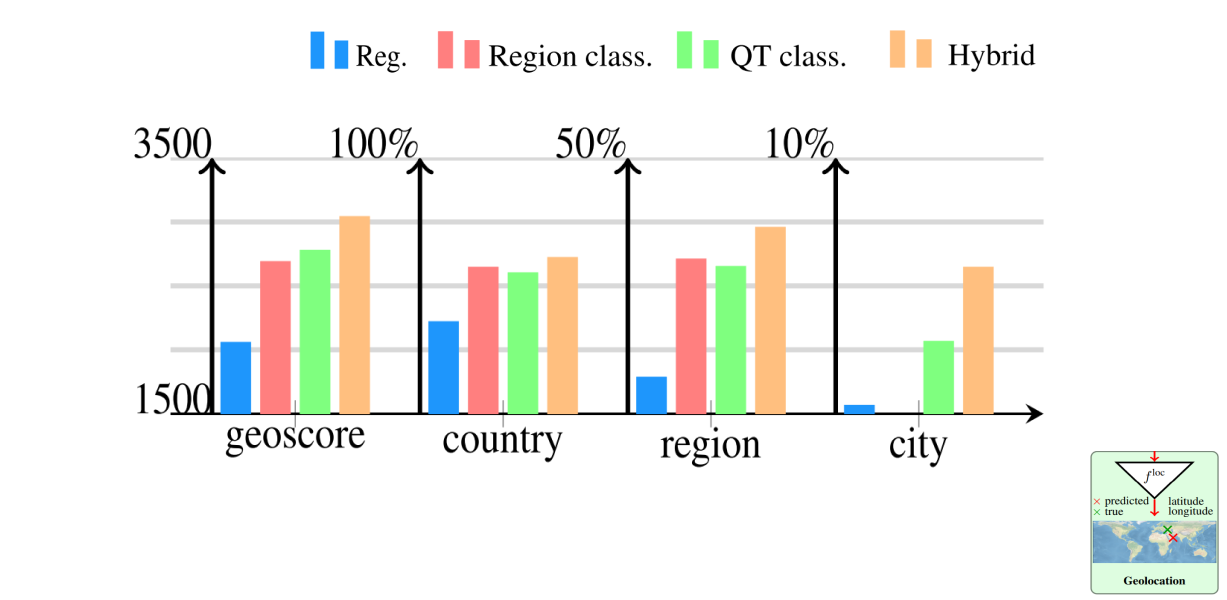
Prediction Head
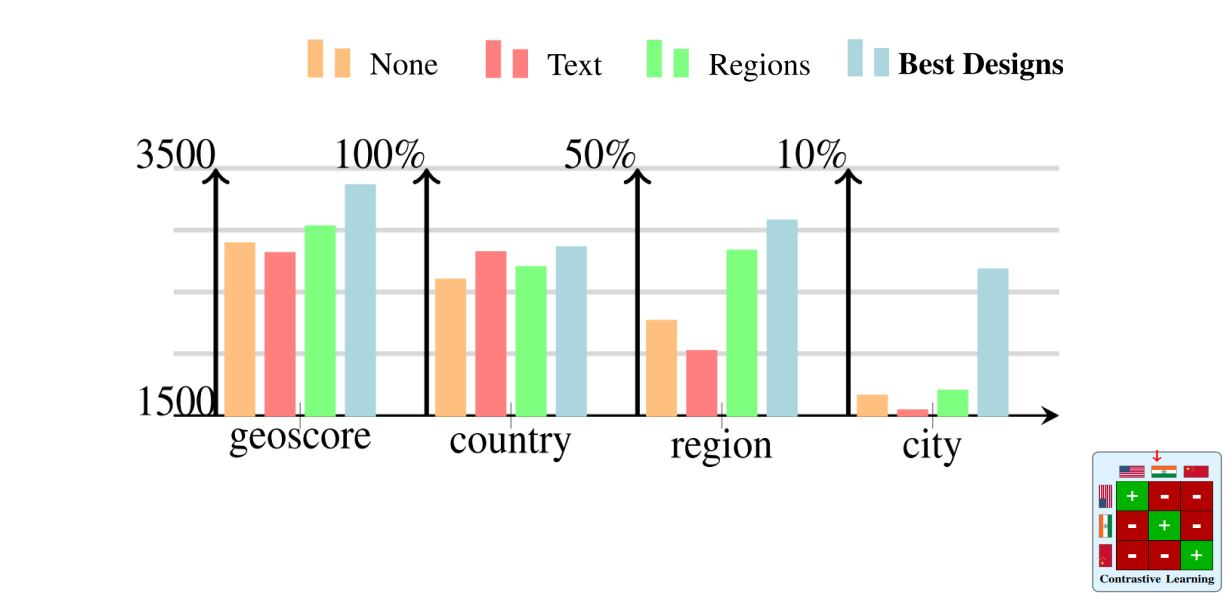
Contrastive
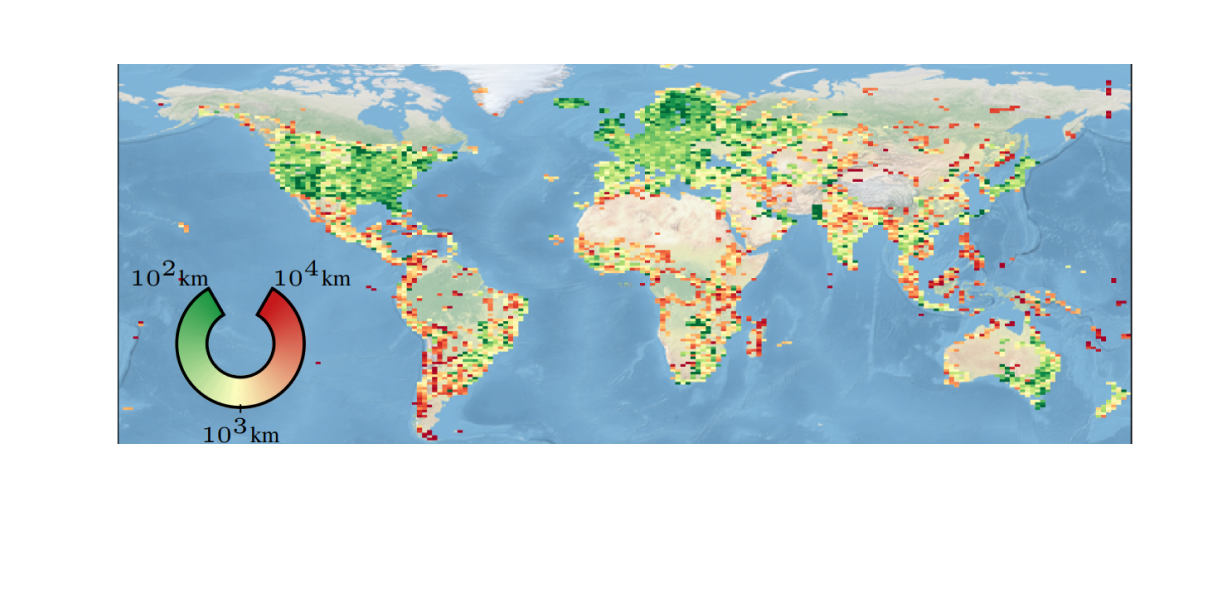
Error Map
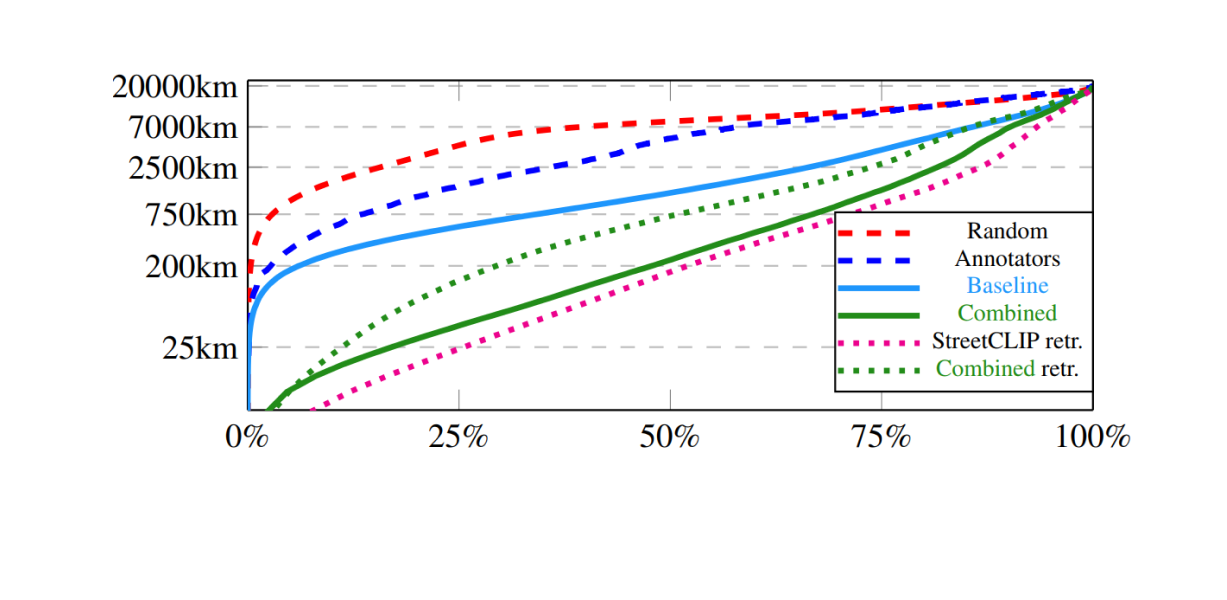
Error Distribution
Key Takeaways
Backbone: Pretraining with the correct data can lead to the same performance as significantly increasing the number of parameters, but with significantly less cost.
Prediction Heads: Classifying with cell partitions (quadtrees) instead of administrative regions leads to higher performance. Hybrid classification-then-regression performs best.
Finetuning: While full finetuning gives the best performance, unfreezing the last transformer block is both more efficient and faster to train than using LoRA, suggesting that the pretrained models can extract relevant early features: only the way of combining them is what needs to be adapted for geolocation.
Contrastive: Using regions to define the positive pairs in the contrastive loss outperforms text/image contrastive approaches.
Presentation
Cite Us
@article{osv-5m,
title = {OpenStreetView-5M: The Many Roads to Global Visual Geolocation},
author = {Astruc, Guillaume and Dufour, Nicolas and Siglidis, Ioannis
and Aronssohn, Constantin and Bouia, Nacim and Fu, Stephanie and Loiseau, Romain
and Nguyen, Van Nguyen and Raude, Charles and Vincent, Elliot and Xu, Lintao
and Zhou, Hongyu and Landrieu, Loic},
journal = {CVPR},
year = {2024},
}
Acknowledgments
OSV-5M was made possible through the generous support of the Mapillary team, which helped us navigate their vast street view image database. Our work was supported by the ANR project READY3D ANR-19-CE23-0007, and the HPC resources of IDRIS under the allocation AD011014719 made by GENCI. We thank Valérie Gouet for her valuable feedback and Ségolène Albouy for helping us make gradio-folium clickable (!).